Week 2 [Mon, Jan 19th] - Topics
Guidance for the item(s) below:
Given this is a first course in SE, tradition demands that we start by defining the subject. However, let's not spend a lot of time going through lengthy/formal definitions of SE. Instead, let's look at an extract from the very first chapter of a very famous SE book, with the aim of providing some inspiration, but also an appreciation of the challenges ahead.
Guidance for the item(s) below:
Now, let's switch our focus to the project management aspect of SE.
Broadly speaking, there are two approaches to doing a software project. Those two approaches are also highly relevant to the way this course is run, and how it is different from most SE courses elsewhere.
Let's learn about those two approaches early so that we can better understand how this course works.
The sequential model, also called the waterfall model, views software development as a linear process, in which the project is seen as progressing through the development stages. The name waterfall stems from how the model is drawn to look like a waterfall (see below).
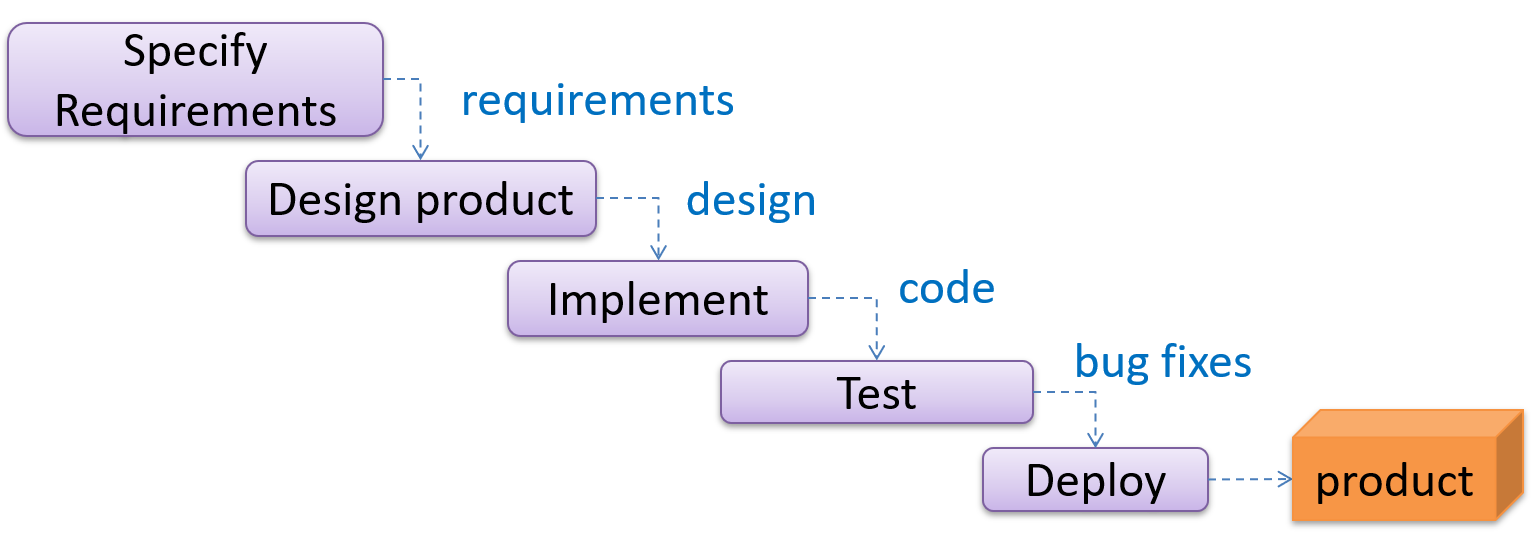
When one stage of the process is completed, it produces some artifacts to be used in the next stage. For example, the requirements stage produces a comprehensive list of requirements, to be used in the design phase.
A strict sequential model project moves only in the forward direction i.e., each stage is completed before starting the next. For example, once the requirements stage is over, there is no provision for revising the requirements later.
This model can work well for a project that produces software to solve a well-understood problem, in which case the requirements can remain stable and the effort can be estimated accurately. Furthermore, as each stage has a well-defined outcome, it is easy to track the progress of the project because one can gauge the project progress by monitoring which stage the project is in.
However, real-world projects often tackle problems that are not well-understood at the beginning, making them unsuitable for this model. For example, target users of a software product may not be able to state their requirements accurately at the start of the project, if they have not used a similar product before.
The iterative model advocates producing the software by going through several iterations. Each of the iterations could potentially go through all the stages of the SDLC, from requirements gathering to deployment.
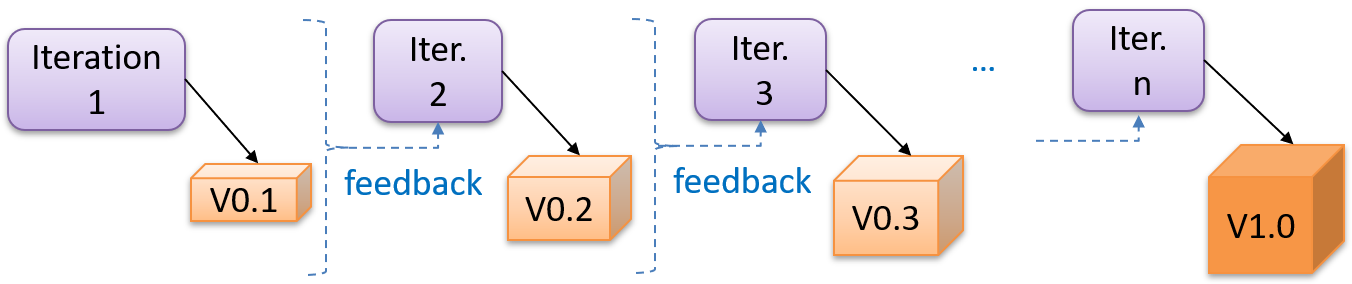
Each iteration produces a new version of the product, building upon the version produced in the previous iteration. Feedback from each iteration is factored into the subsequent iterations. For example, if an implementation task took longer than expected, the effort estimate for a similar tasks in future iterations can be adjusted accordingly. Similarly, if a feature introduced in the current iteration was not well-received by target users, it can be removed or tweaked in the next iteration.
The iterative model can be done in breadth-first or depth-first approach.
- In the breadth-first approach, an iteration evolves all major components and all functionality areas in parallel i.e., most features and most will be updated in each iteration, producing a working product at the end of each iteration.
- In the depth-first approach, an iteration focuses on fleshing out only some components or some functionality area. Accordingly, early depth-first iterations might not produce a working product.
Taking a Minesweeper game as an example,
- breadth-first iterations will deliver a fully playable version early. These early versions may have primitive functionality, for example, a rudimentary text based UI, fixed board size, limited minefield layouts, etc. These functionalities (and corresponding components) will then be improved in later releases.
- an early depth-first iteration could deliver the full user interface (UI) but with no game logic at all. Alternatively, an early iteration could focus on just the logic for generating initial layouts of the minefield. Neither will be a playable version of the game but both can be used to collect early feedback (about the UI, and the initial minefield layouts, respectively) which can then be used to guide later iterations.
A project can be done as a mixture of breadth-first and depth-first iterations i.e., an iteration can contain some breadth-first work as well as some depth-first work, or, some iterations can be breadth-first while others are depth-first.
Follow up notes for the item(s) above:
Scanning a TLDR version of a topic: As mentioned in 'Using this Website' page, the more important layer of information is given in bold text. For example, you can quickly scan the essential points of a topic by reading the bold text only (this could be useful when you want to quickly recap a previous topic, or to get an idea of what a topic covers without reading all the details).
Guidance for the item(s) below:
Next, let's resume our Git Learning Trial, covering a few more tours. the first two focus on working with GitHub, while the other two focus on getting more out of the Git revision history.
Guidance for the item(s) below:
As you are likely to be using an IDE for the iP, let's learn at least enough about IDEs to get you started using one.
🤔 In case you are puzzled by the sudden change of topic, it's because we take an iterative approach to covering topics, as explained in the panel below:
Guidance for the item(s) below:
As you start adding features to your project iteratively, you'll need a way to detect if the new code breaks the existing code. Next, let's learn a rather simple way to do that using a certain type of testing (we'll be learning more sophisticated methods in later weeks).
This also means we are now switching focus from the implementation aspect to the testing aspect of SE.
Testing: Operating a system or component under specified conditions, observing or recording the results, and making an evaluation of some aspect of the system or component. –- source: IEEE
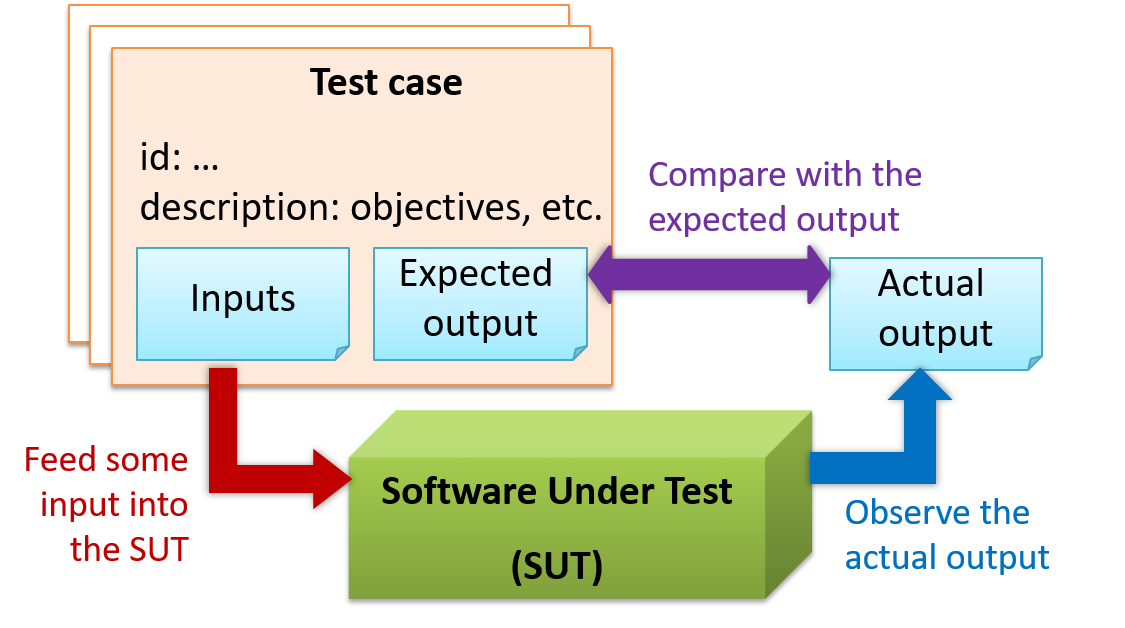
When testing, you execute a set of test cases. A test case specifies how to perform a test. At a minimum, it specifies the input to the software under test (SUT) and the expected behavior.
Example: A minimal test case for testing a browser:
- Input – Start the browser using a blank page (vertical scrollbar disabled). Then, load
longfile.htmllocated in thetest datafolder. - Expected behavior – The scrollbar should be automatically enabled upon loading
longfile.html.
Test cases can be determined based on the specification, reviewing similar existing systems, or comparing to the past behavior of the SUT.
For each test case you should do the following:
- Feed the input to the SUT
- Observe the actual output
- Compare actual output with the expected output
A test case failure is a mismatch between the expected behavior and the actual behavior. A failure indicates a potential defect (or a bug) -- we say 'potential' because the error could be in the test case itself.
Example: In the browser example above, a test case failure is implied if the scrollbar remains disabled after loading longfile.html. The defect/bug causing that failure could be an uninitialized variable.
Follow up notes for the item(s) above:
Congrats! You've made it to the end of this week's topics. It feels like a lot right now but now that we got an early start, this stuff will be second nature to you by the time you are done with the semester. 😃